Mise en place d'un projet pour la prospection en forêt
Je vous propose donc un exercice/simulation/exemple... Enfin je suppose que vous voyez ce que je veux dire. On va se mettre en condition et ce sera l'occasion de réfléchir à la structure des données, la mise en place de la base de données et des stratégies d'enregistrement.
En parallèle de ce document, j'ai aussi réalisé un support pour réaliser une base de données en SQLite, avec le même exemple de base : Les bases de données du MIAOU.
Structure de la base
Comme je l'ai dit, je pars du principe que vous connaissez les formats de données utilisés en SIG, que vous maîtrisez les projections, enfin que vous avez déjà un petit niveau en géomatique (et sinon, vous pouvez vous former avec ces vidéos). Bon, c'est fait ? Vous vous êtes formés ? Parfait, on poursuit  .
.
Besoins du projet
La première chose à faire est de choisir ce que nous allons enregistrer, comment et ce dont nous aurons besoin. N'oubliez pas qu'une base de données est une organisation de données qui correspond à la façon dont nous percevons et interprétons nos données de recherche. Il n'y a donc pas de base unique et elle va forcément évoluer. Donc on peut se planter, ne pas choisir les bonnes variables, rien n'est grave, on peut toujours corriger après coup ! 
L'exemple que nous allons suivre avec les choix pris a été fait dans le cadre de la formation master/apprentis/doctorat de l'Université Paris 1 en archéologie (donc si vous êtes pas d'accord ou que vous trouvez ça nul, c'est pas gentil parce que vous vous en prenez à des gens en formation (et ça, c'est vraiment mal  ))
))
Nous allons préparer un projet pour prospecter en forêt. Nous enregistrerons les anomalies (dans un sens large et un peu flou), les structures et le mobilier. Pour des raisons pratiques et organisationnelles, nous allons aussi créer des zones arbitraires qui nous aideront à cadrer nos prospections et nous utiliserons une couche de tracking qui permettra de voir où nous sommes allés concrètement.
Les champs qui composent ces tables sont :
Mobilier
géométrie → points
- Identifiant : Un nom ou identifiant un peu explicite que nous pourrons utiliser.
- zone : La zone de prospection dans laquelle l'entité a été relevée.
- nature : Son matériau global.
- contexte particulier : Si c'est dans un chablis ou une taupinière, ce genre d'info.
- date de création : Horodatage de la création de l'entrée.
- dernière modification : Horodatage de la dernière modification (ça peut être rapidement utile quand on essaie de comprendre l'historique de la donnée).
- auteurice : C'est qui qu'a rempli cette entrée ?
- photographie : Une petite photo du mobilier (Si c'est utile, les photos floues de racines, par exemple, on peut éviter...).
- commentaires : Il y a toujours des trucs qui vont pas dans les petites cases, alors je laisse toujours un espace de liberté narrative
 .
.
Structure
géométrie → polygones
- Identifiant : Un nom ou identifiant explicite.
- zone : La zone de prospection .
- nature : Élévation ? Fossé ? Autre ? (enfin vous avez l'idée)
- état : Est-ce que c'est bien préservé ?
- date de création : Horodatage de la création de l'entrée.
- dernière modification : Horodatage de la dernière modification.
- auteurice : Qui a rempli cette entrée ?
- photographie : La photo souvenir.
- commentaires : Les trucs en plus
 .
.
Anomalies
géométrie → polygones
Les anomalies, c'est vraiment une indication générale sur des trucs pas vraiment caractérisés, donc la table est forcément un peu simple et généraliste.
- description : je pense que vous avez saisi l'idée.
- zone : La zone de prospection.
- date de création.
- dernière modification.
- auteurice.
Zones
géométrie → polygones
Les zones sont créées en amont des prospections, c'est uniquement un cadre pour nous aider à marcher au bon endroit, pas besoin de reconstituer l'historique de la donnée  .
.
- nom : Même un petit carré mérite d'avoir une identité.
- priorité : Stratégie, tout ça.
- fait ? : fait ou pas encore ?
- commentaires : Parce qu'on sait jamais.
Tracking
géométrie → lignes
- date : Quand est-ce que la balade a eu lieu.
- gens : Qui marchait ensemble ?

Pas besoin de plus de description, sauf si vraiment j'ai des retours de lectrices et lecteurs qui veulent encore plus d'explications...
Modèle entités-relations (ERD)
Un ERD (Entity Relationship Diagram), c'est un schéma dans lequel sont indiquées les tables et les relations et les champs. C'est la structure opérationnelle de notre base et c'est ce que nous allons suivre pour la mise en place de notre base en format geopackage. Dans cet ERD, je vais en profiter pour indiquer les types de champs qui composent les tables (par exemple du texte, des nombres, etc. (si ça ne vous parle pas trop trop  (j'ai pas trouvé d'âne... ça fait la chêvre trotro, elle est peut-être moins rigolote), allez faire quelques révisions sur les bases de données, ça pourra être utile)), si on utilise des listes de valeur et enfin si on va les remplir de façon automatique. À côté du type de champ, je rajoute "LV" pour liste de valeur et "A" pour automatique (je sais, c'est pas révolutionnaire et ça manque cruellement de poésie, mais c'est la faute à la société
(j'ai pas trouvé d'âne... ça fait la chêvre trotro, elle est peut-être moins rigolote), allez faire quelques révisions sur les bases de données, ça pourra être utile)), si on utilise des listes de valeur et enfin si on va les remplir de façon automatique. À côté du type de champ, je rajoute "LV" pour liste de valeur et "A" pour automatique (je sais, c'est pas révolutionnaire et ça manque cruellement de poésie, mais c'est la faute à la société  ). Ah, et pour les nombres entiers, je mets juste "int" pour integer et quand ce sont des clés primaires, je mets PK (Primary key) sans ajouter que ce sont des champs uniques et automatiques (normalement, ça c'est acquis et puis QGIS le gère automatiquement). D'ailleurs, QGIS gère aussi les géométries, donc je ne m'étendrai pas dessus.
). Ah, et pour les nombres entiers, je mets juste "int" pour integer et quand ce sont des clés primaires, je mets PK (Primary key) sans ajouter que ce sont des champs uniques et automatiques (normalement, ça c'est acquis et puis QGIS le gère automatiquement). D'ailleurs, QGIS gère aussi les géométries, donc je ne m'étendrai pas dessus.

Les noms indiqués ici sont ceux que j'utiliserai pour la base, c'est pour ça que je ne mets pas d'accent, d'espace ou de caractères spéciaux. Gardez à l'esprit qu'on peut toujours modifier l'affichage ensuite. Pour les tables, vous avez aussi dû remarquer que celles "classiques" sont nommées avec un "T" et les listes de valeurs avec "L". C'est juste pour s'y retrouver plus facilement, ça n'a pas spécialement de valeur techniques, tout ça, c'est une aide à la lisibilité.
Pour les liens de 1 à n, bon bah une base de prospection, il y a rarement besoin d'avoir des architectures folles, donc c'est relativement simple; seules les zones sont reliées en clé primaire/clé étrangère aux structures, mobilier et anomalies. Si on n'a pas besoin de plus, pas la peine de tout compliquer.
Pour les listes de valeur, j'ai ajouté un champ de définition pour certaines, ça peut être utile, surtout si vous travaillez à plusieurs. Vous pouvez utiliser un vocabulaire contrôlé comme Pactols, par exemple.
Enfin, certaines tables ont des géométries, mais pas toutes. Alors déjà, toutes les tables deviendront des couches dans le SIG et toutes les couches n'ont pas besoin de posséder une géométrie, je vous montrerai quand on y sera.
Création de la base dans QGIS
On est prêts, c'est bon, on va se lancer ! 
Un rappel : On est dans QGIS. Même si on crée notre base de données à travers un projet, il faut bien séparer les deux, projet et base sont deux objets différents que nous utilisons en parallèle. Un même projet peut être connecté à de multiples bases et une base peut être utilisée dans plein de projets différents. Pour la gestion des geopackage, vous avez pas mal de ressources en ligne et même la documentation techniques officielle (un peu ardue, mais pourquoi ne pas aller y jeter un oeil).
On met notre projet en EPSG 3949 (on va dire qu'on travaille en région parisienne, la projection est donc CC49 (zone 8)) et on enregistre le tout. C'est plus simple de commencer par paramétrer le projet, comme ça, la projection sera directement proposée à la création de chaque nouvelle couche.
Tables (couches) GeoPackage
Maintenant : Couche → Créer une couche → Nouvelle couche GeoPackage...
Une nouvelle fenêtre s'ouvre :
- File name : On clique sur les ... en fin de ligne et on choisit un dossier où enregistrer le geopackage. N'oubliez pas, c'est la base de données, pas une couche, donc en général on lui donne le nom du projet.
- Ensuite la table elle-même : T_structures (puisque c'est celle-ci que je crée pour l'exemple).
- Géométrie : Polygone (comme dans l'ERD).
- SCR (la projection quoi) : J'ai mis celle du projet (c'est la même que l'EPSG 3949, ça ne change presque rien).
- Et maintenant on crée les champs comme dans l'ERD !

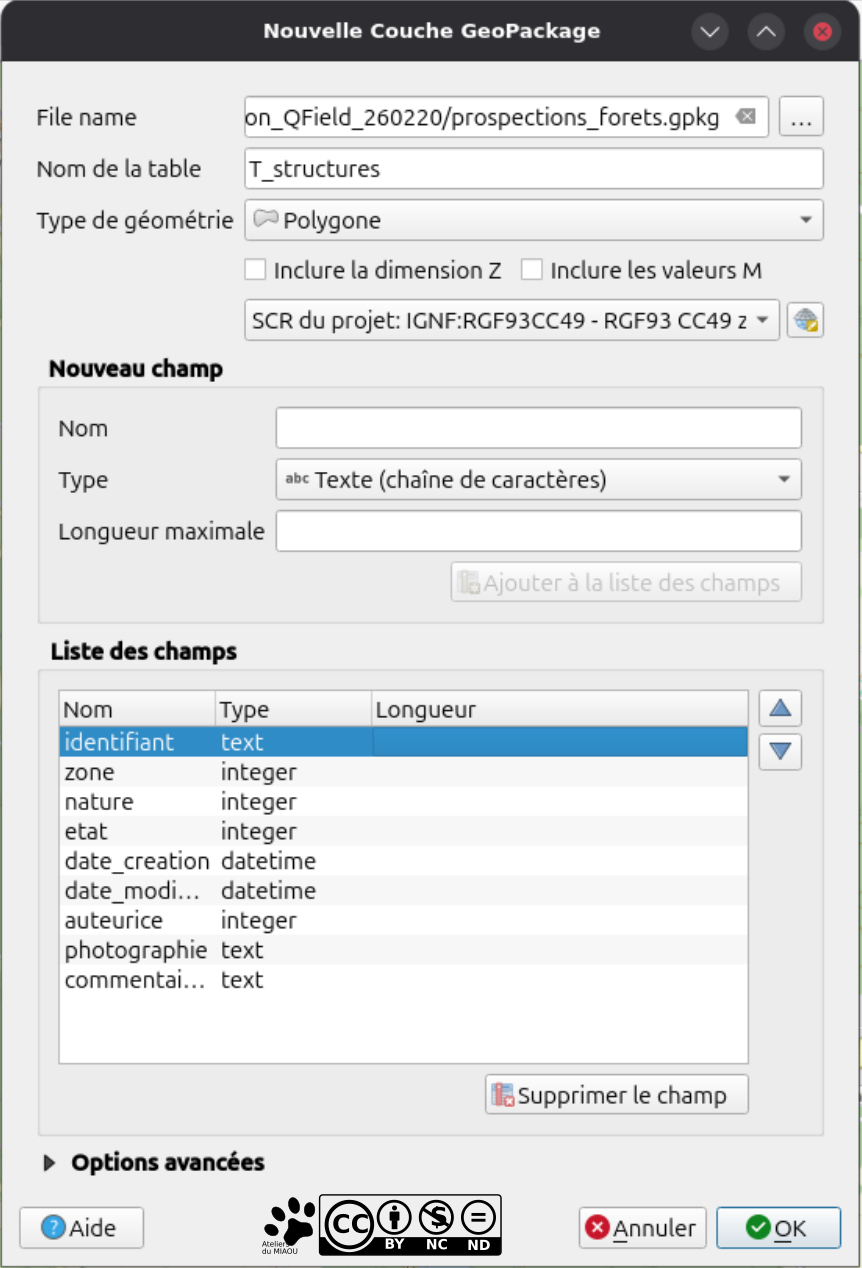
Pour les autres tables, il faudra choisir le geopackage existant dans File name, s'il vous propose de le remplacer (sur Mac et Linux ça fait souvent ça), dites que "ouais ouais, pas de problèmes, ça me fait pas peur" !  En revanche, une fois la nouvelle couche créée, sélectionnez "ajouter la couche" et surtout pas "Écraser" !
En revanche, une fois la nouvelle couche créée, sélectionnez "ajouter la couche" et surtout pas "Écraser" ! 
Pour les tables créées via cet outil, pas besoin de gérer la clé primaire, QGIS le fait pour vous, c'est gentil quand même !
Tables textuelles
Pour les listes de valeurs, je vais en profiter pour vous montrer une autre méthode (je sais, le monde est fou  ). On va passer par le gestionnaire de bases de données : Bases de données → Gestionnaire de bases de données.
). On va passer par le gestionnaire de bases de données : Bases de données → Gestionnaire de bases de données.
Si votre nouveau GeoPackage n'apparaît pas, surtout pas de panique ! En revanche, ne vous retournez pas, il y a un monstre derrière vous...  Plus sérieusement (on n'est quand même pas là pour rire non plus, c'est tellement sérieux et important ce qu'on fait
Plus sérieusement (on n'est quand même pas là pour rire non plus, c'est tellement sérieux et important ce qu'on fait  ), il suffit de s'y connecter (dit comme ça, ça nous avance vachement
), il suffit de s'y connecter (dit comme ça, ça nous avance vachement  ). Clic droit sur GeoPackage → Nouvelle connexion... et là vous allez chercher votre cher geopackage de prospections dans la forêt.
). Clic droit sur GeoPackage → Nouvelle connexion... et là vous allez chercher votre cher geopackage de prospections dans la forêt.
Bon maintenant que tout est là, on déplie sa base GeoPackage pour activer la connexion puis Table → Créer une table.... Maintenant, il faut ajouter les champs comme dans l'image (rien d'hyper perturbant). Deux éléments à retenir ici, cet outil ne gère pas lui-même les clés primaires et il faut donc les créer soi-même, pensez aussi à cocher la case "Null" pour les champs dont le remplissage n'est pas obligatoire (c'est une autorisation pour que le champ soit nul et, en général pour les définitions ou les commentaires, c'est pas toujours obligé de le remplir).
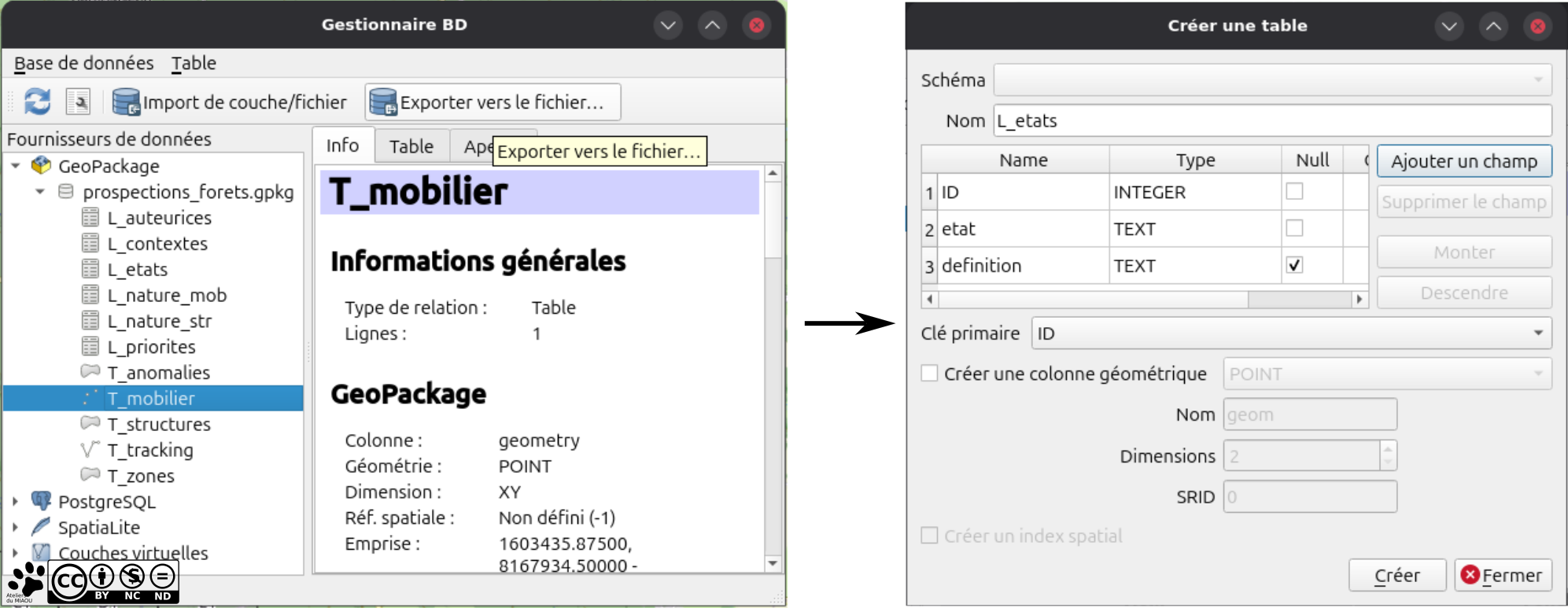
Je vous laisse faire toutes les tables dont nous avons besoin pour la base, vous pouvez prendre votre temps, moi je vais aller me chercher un café... 
Gérer les liens
Pour les liens de 1 à n, il faut les créer via le logiciel QGIS (ils ne sont pas écrits directement en SQL dans le GeoPackage, c'est plus simple ici). Un truc important, c'est qu'on les fait par rapport au nom affiché des tables. Par exemple, pour une lecture facilitée et un rendu plus esthétique, j'ai modifié le nom de mes tables en retirant le "T_" et en mettant une majuscule au nom, ça fait plus chic  . Donc si on commence par les liens et qu'on modifie les noms affichés ensuite, bah ça perd tout, donc on peut commencer par modifier les noms si vous voulez (moi je l'ai fait, vous, bah vous êtes libres
. Donc si on commence par les liens et qu'on modifie les noms affichés ensuite, bah ça perd tout, donc on peut commencer par modifier les noms si vous voulez (moi je l'ai fait, vous, bah vous êtes libres  ).
).
C'est bon ? On va sur l'onglet Projet → Propriétés → Relations. Normalement, cette fenêtre est vide et vous pouvez ajouter les relations en cliquant sur le gros  (vert) Ajouter une relation. Ensuite, comme dans l'image (ici avec l'exemple de la relation de zone à mobilier):
(vert) Ajouter une relation. Ensuite, comme dans l'image (ici avec l'exemple de la relation de zone à mobilier):
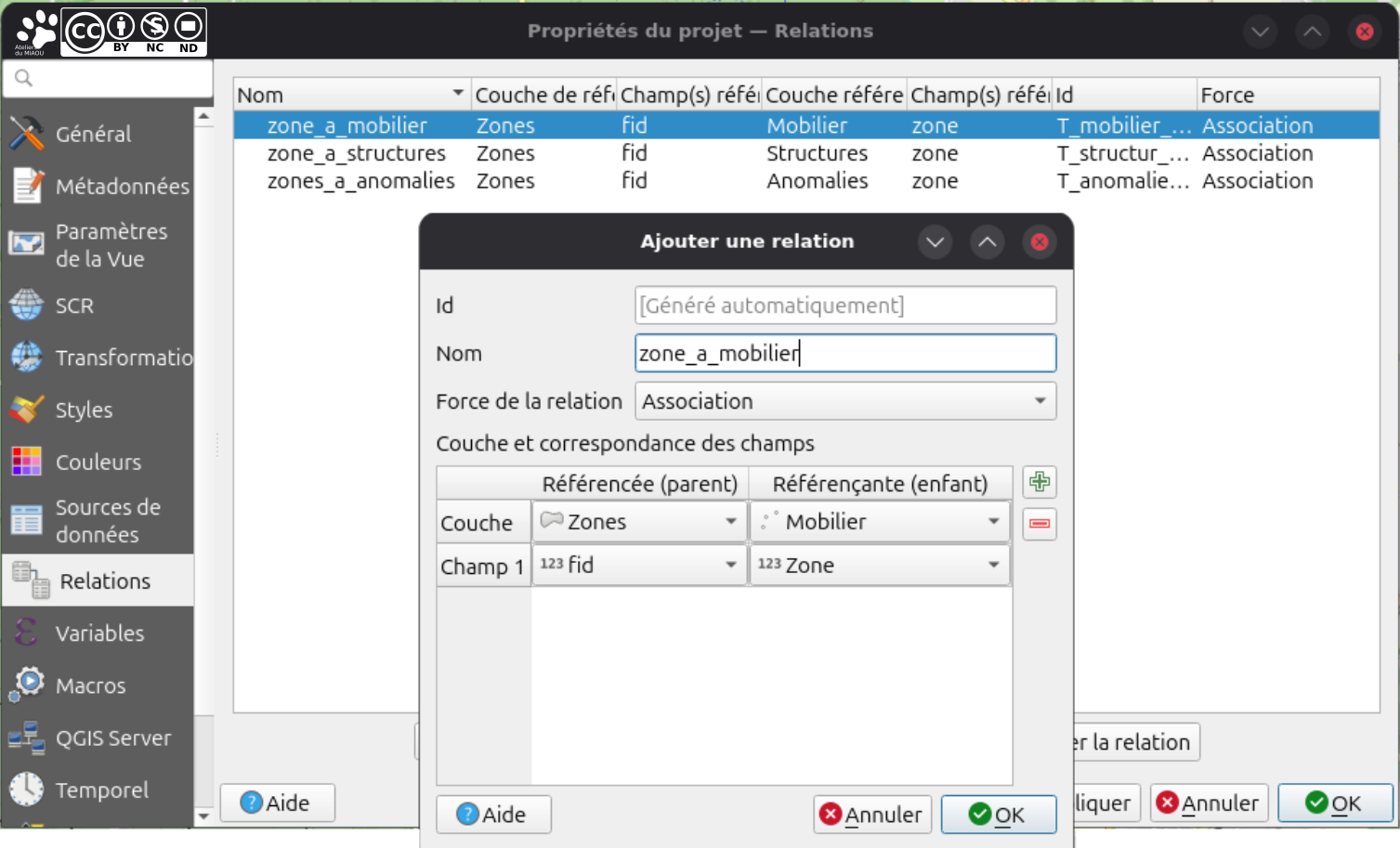
Le référencé, c'est le côté 1, celui d'où vient l'information - on choisit donc la clé primaire comme champ- et le référençant, le côté n où arrive l'information - là c'est le champ du lien où on va stocker la clé primaire (qui devient donc une clé étrangère dans cette table).
Ensuite, la force de la relation  . Vous avez le choix entre deux options :
. Vous avez le choix entre deux options :
- Association : si on supprime un objet référencé, le parent, l'entité référençante, l'enfant, reste. Ça donne une entité orpheline (c'est le vrai langage technique bien joyeux et ambiançant des bases de données
 ). Dans notre cas, cela signifie que si on supprimes une zone qui possède du mobilier, le mobilier enregistré reste et son champ zone devient
). Dans notre cas, cela signifie que si on supprimes une zone qui possède du mobilier, le mobilier enregistré reste et son champ zone devient NULL. - Composition : si tu supprimes un objet parent, les enfants liés sont automatiquement supprimés aussi (au moins, pas d'orphelins
 ). Pour notre exemple, si on supprime une zone qui possède du mobilier, ça supprimera aussi le mobilier lié.
). Pour notre exemple, si on supprime une zone qui possède du mobilier, ça supprimera aussi le mobilier lié.
Quand on ne veut pas se prendre la tête, on met souvent Association par défaut. C'est souvent un peu de la flemme et il y a régulièrement des cas pour lesquels il faut utiliser Composition. Par exemple, dans les structures, on aurait pu créer des sous-structures et dans ce cas, ça devient compliqué d'avoir une sous-structure non associée à une structure. La supression de l'entité principale entraîne celle de ses sous-entités, c'est beaucoup plus simple à gérer et évite les entités orphelines.
Si tout est bon, vous pouvez faire les deux autres liens (comme ça, je me reprends un café ).
Préparation depuis QGIS pour son déploiement dans QField
QField ne permet pas de modifier la symbologie, les nommages automatiques, enfin tous ces trucs qu'on règle dans les propriétés d'une couche. Il faut donc tout régler en amont et c'est le temps pour une petite liste pense-bête.
- Formulaires de saisie adaptés
- Symbologie (paramètres et réactions)
- Nommage des entités
(normalement, ça fait des cases à cocher, mais là, je sais pas ça fonctionne pas  )
)
Les formulaires
Jusqu'ici, on a un SIG classique et puis des données structurées. C'est pas mal, mais on est encore loin d'une belle base de données qui fera rougir de jalousie (:information_desk_person:) vos camarades et concurrent.e.s ! Il manque effectivement les formulaires, ces trucs avec des cases à cocher, des menus déroulants et des séparateurs colorés inutiles "mais ça fait pro", alors on va s'y mettre.
C'est relativement simple, on va dans les propriétés d'une couche et là, "Formulaire d'attribut". Vous avez maintenant les champs de votre table disponibles devant vous.
Première chose, sur la petite barre en haut, on change Génération automatique pour Conception par glisser/déplacer. Vous devriez avoir deux colonnes, la première pour les champs disponibles, Available widgets, et l'autre pour ceux qui sont dans le formulaire, Form layout. Pour l'ensemble des manipulations, vous pouvez consulter cette chaîne YouTube - Remeuze.
Les photos dans QField
Pour les photos, c'est un peu différent et je ne sais plus si je le mentionne dans les vidéos (et AUCUNE envie d'aller les revoir de mon côté). Dans les bonnes pratiques des bases de données, on ne stocke pas directement des vidéos. On fait simplement un lien vers et le logiciel de gestion de base de données s'occupe d'afficher une miniature de l'image. Dans la table, un champ pour une photographie est de type texte (puisqu'on enregistre le chemin vers la photographie) et dans le formulaire, on choisit le type de widget (ou type d'outil, je sais jamais si et comment c'est traduit...) → "pièce jointe". Pour emplacement, on choisit Relatif au chemin du projet et dans le visualiseur intégré, on choisit image, comme ça l'image sera affichée et QField reliera automatiquement ce champ à l'appareil photographique de votre outil portable.
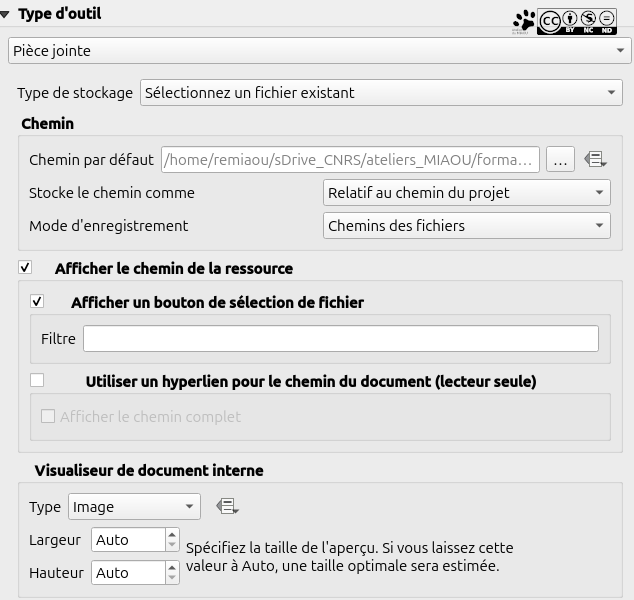
De plus, une fois le plugin QFieldSync installé, vous pouvez modifier les option de nomamge des photos dans les propriétés de la couche :
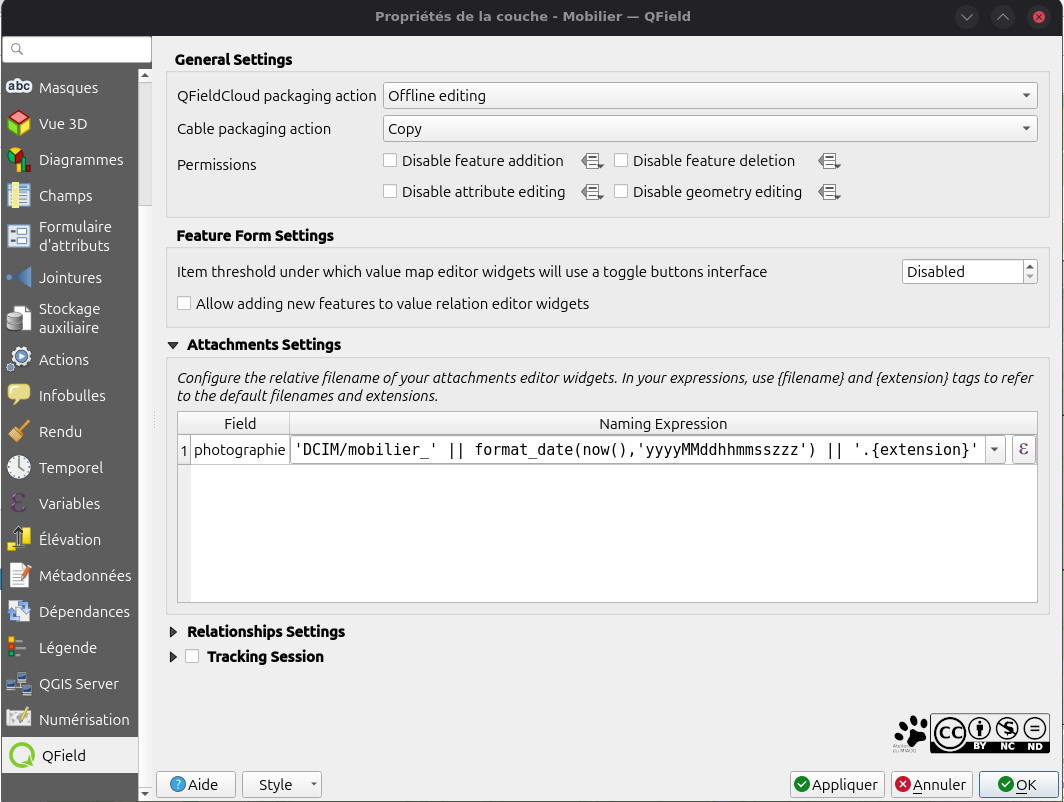
La syntaxe est identique à la calculatrice de champs, le début, DCIM/, indique le dossier (c'est la / qui indique une position de dossier, comme il n'y a rien avant DCIM, le logiciel créera le dossier d'enregistrement dans le dossier de travail). Ensuite, QField met le nom de la couche par défaut puis, dans l'exemple de la capture d'écran ci-dessus : || pour concaténer (juxtaposer des trucs dans le code sans calcul nie rien entre les arguments de part et d'autre de la double barre), puis la date formatée (j'en parle dans d'autres supports et c'est facile à trouver) et enfin l'extension. Voilà, prêt.e pour les photos ? Alors on continue ! 
En dehors des photos, je vous laisse découvrir les modalités des formulaires par vous-même et avec la documentaiton existante (genre les vidéos déjà indiquées, je vais pas encore le re-répéter ).
:bulb: Les formulaires de saisie peuvent être un peu capricieux, le comportement de QField évolue énormément, donc il faut tester. De toute façon, je l'ai beaucoup répété (à l'oral, donc faites semblant d'avoir été en cours même si vous n'êtes pas étudiant.e, c'est pour la cohérence narrative), le plus long, c'est le crash test, faut tout le temps faire des allers-retours.
Symbologie
Comme rien n'est modifiable facilement depuis QField (normalement, rien n'est modifiable mais au cas où ça le devient, je mets un "normalement" pour ne pas avoir à changer le texte dans deux jours  ), pensez à bien gérer votre symbologie. Ici, je vais vous montrer un seul exemple, mais un truc chouette. Si vous faites une symbologie réactive, c'est-à-dire qu'elle modifiera l'aspect des entités si vous en modifiez les informations liées, ça fonctionnera aussi dans QField. Dans l'exemple qui suit, on va faire en sorte que les carrés des zones de prospections soient de couleur et que celle-ci change en fonction de leur priorité et s'ils ont été prospectés, comme dans l'image suivante.
), pensez à bien gérer votre symbologie. Ici, je vais vous montrer un seul exemple, mais un truc chouette. Si vous faites une symbologie réactive, c'est-à-dire qu'elle modifiera l'aspect des entités si vous en modifiez les informations liées, ça fonctionnera aussi dans QField. Dans l'exemple qui suit, on va faire en sorte que les carrés des zones de prospections soient de couleur et que celle-ci change en fonction de leur priorité et s'ils ont été prospectés, comme dans l'image suivante.
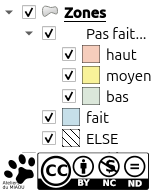
On veut donc que la zone s'affiche en rouge pour une priorité haute, jaune pour moyenne et vert pour basse, et si la zone est faite, elle passe en gris léger.
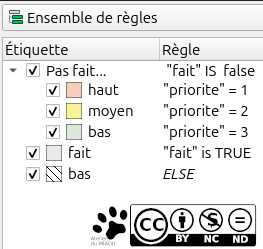
Pour ça, on va dans "symbologie", puis, pour ne pas tout faire à la main (rassurez-vous, il faudra gérer des trucs manuellement tout de même), on va sur "gradué" et on choisit la colonne "priorité" et enfin "classer". Vous avez un premier classement sur les niveaux de priorité, il ne reste plus qu'à en reprendre les couleurs (avec une bonne transparence parce qu'on veut quand même voir le fond de carte à travers). Maintenant, on va imbriquer les règles, il faut passer en manuel. Pour ça, on change "Gradué" pour "Ensemble de règles", normalement votre symbologie liées aux niveaux des priorités est conservés, et vous pouvez cliquer sur le gros + vert. Là, on veut ajouter la condition "fait ou pas", indiquée par la colonne booléenne Fait.
Commençons par les priorités qui ne s'affichent que si la zone n'a pas été prospectée. Pour ça, après avoir cliqué sur le gros plus, on choisit une symbologie → on décoche le symbole car on veut que rien d'autre que nos couleurs de priorités s'affichent, puis une étiquette et une règle (d'où le nom, comme quoi le monde est bien fait quand même !) "fait" is FALSE. On ajoute et là, on peut faire glisser les autres lignes (celles des priorités) pour les inclure dans "fait" is FALSE. Comme ça, les couleurs des priorités ne s'afficheront que si la zone n'a pas été prospectée. On ajoute une nouvelle règle, on choisit une symbologie (normal  ) et là, on va mettre un gris transparent. Si tout est comme dans l'image suivante, c'est tout bon.
) et là, on va mettre un gris transparent. Si tout est comme dans l'image suivante, c'est tout bon.
On a fait dans ce sens (afficher les couleurs des priorités si
"fait" is FALSEet pas de condition supplémentaire si"fait" is TRUE) parce que pour des raisons pratiques, vous n'allez pas revenir modifier la colonne priorité quand vous aurez prospecté une zone. Une fois faite, vous n'avez qu'à la cocher et passer à la suivante. J'ai aussi rajouté un ELSE, c'est lesinonque vous pouvez choisir à la place defiltrequi permet de capturer toutes les entités qui ne tombent pas dans les règles, genre celle dontfaitestNULLet qui n'ont pas de priorité.
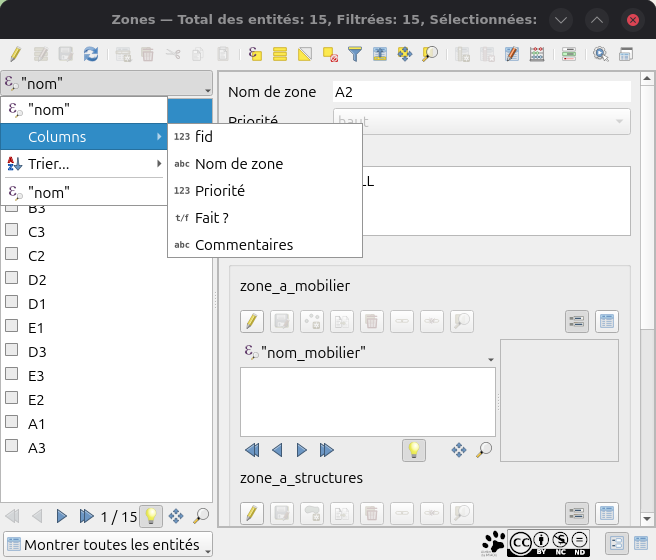
Nommage des entités
Il faut aussi nommer les entités. Comme on a fait une jolie base avec des clés primaires, des identifiants, tout ça, la colonne choisie automatiquement par QGIS pour nommer simplement les entités n'est pas toujours la bonne. Le plus simple, c'est d'aller dans la table attributaire de la couche et de passer en affichage "Formulaire". Là → sur la colonne sur l'entête de la colonne où s'affichent les noms et vous pouvez sélectionner une colonne spécifique ou même mettre une règle, pour, par exemple, ajouter des informations de contexte dans l'affichage du nom (ça peut toujours être utile quand on est mal réveillé et qu'on prospecte en forêt sous la pluie  ).
).
Maintenant que (presque) tout est (plus ou moins) prêt, on va passer à la synchronisation et au travail entre ordinateurs et supports portables !
Allez, zou, vers les échanges synchronisation de données !